Grupo de Trabajo:
Hace un año lanzamos un nuevo grupo de trabajo de DAMA España dedicado a la Ciencia de Datos y al Machine Learning, con el objeto de ampliar la acción de DAMA y su contribución a través de los grupos de trabajo al ámbito de la Inteligencia Artificial y más en concreto al ámbito en que una rama tan amplia como es la inteligencia artificial se encuentra con la incertidumbre y la probabilidad, y trata de extraer predicciones a partir de la búsqueda de patrones de datos.
Varios profesionales de distintos sectores, pese a la dificultad que supone sumar una tarea adicional a la vida personal y profesional, constituimos el equipo y nos enfrentamos a la primera gran decisión, que no era otra que establecer un objetivo que limitase las amplias posibilidades de dedicación a un espacio acotado que nos motivase a todos y que nos permitiese desarrollar el grupo de trabajo de una forma ordenada y unificar los esfuerzos en torno a ese objetivo.
Quizás debido a que ya resonaban en aquel tiempo de fondo los tambores de una ley de la Unión Europea para introducir principios éticos en la inteligencia artificial o quizás no; pero fuese como fuese, finalmente nos decantamos por desarrollar el grupo explorando técnicas de datos que nos permitiesen trasladar esos principios éticos a los algoritmos.
La concreción de este objetivo, también supuso una tarea reseñable, en la que desarrollamos un estudio o modo de “estado del arte” sobre la aplicación de los principios éticos en las compañías con mayor avance en el desarrollo de Inteligencia Artificial; para mediante clasificación y ordenación, establecer los que consideraríamos principales ejes dentro del objetivo del equipo.
De este modo definimos los ejes agrupadores de las iniciativas y líneas de trabajo del grupo; que son:
- Neutralidad
- Explicabilidad
- Monitorización y Control
- Responsabilidad
- Privacidad y Gobierno
La idea que subyace y que se convierte desde ese momento en la misión del equipo, es la de desarrollar estos ejes considerándolos en todo el ciclo de vida de un proyecto de Data Science.
En la siguiente figura, se puede ver como partiendo del proceso de Data Science publicado en el DMBOK, hemos incluido en el centro un pentágono en el que cada lado representa uno de los 5 ejes establecidos por el grupo de trabajo.
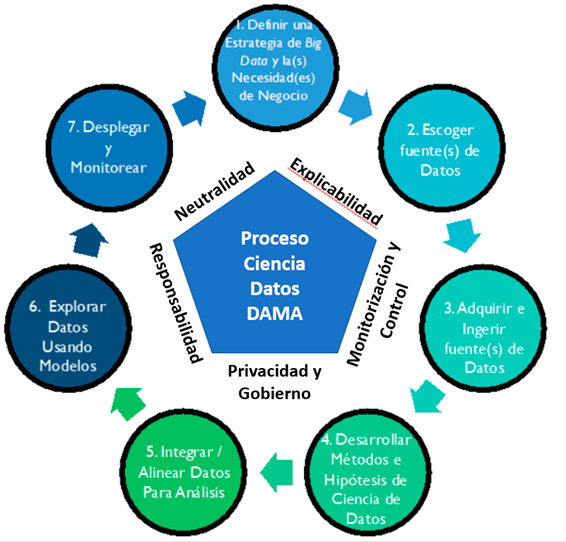
Desde un punto de vista de defensa, el pentágono es una formación clásica en fortificaciones y baluartes, y en nuestro caso creemos que representa el fortín que construimos alrededor de los algoritmos para protegerlos de que puedan presentar comportamientos no éticos.
1) Privacidad y Gobierno: Dentro de este eje tenemos un línea de trabajo recientemente iniciada en la que pretendemos hacer una comparativa de performance en un algoritmo, desarrollando el modelo con privacidad diferencial por un lado y sin ella por el otro.
La Privacidad diferencial es una técnica que permite introducir ruido en los datos sin cambiar significativamente su distribución y sus correlaciones, de modo que no compromete los datos, pero permite extraer de los datos con ruido los patrones y conocimiento que un algoritmo podría extraer de Estamos en una fase inicial, en la que por un lado hemos elegido el problema/datos sobre los que desarrollar la iniciativa, y por el otro nos encontramos
desarrollando un documento para aterrizar las bases formales de la privacidad diferencial y facilitar a todos su comprensión.
2) Neutralidad:
En esta línea de trabajo hemos desarrollado nuestro primer WhitePaper, en el que hemos propuesto técnicas para medir y reducir los sesgos en los algoritmos. Contamos con la ayuda para la revisión de este nuestro primer entregable, del grupo de de trabajo de Ética y Seguridad de DAMA, y fruto de esta colaboración tuvimos la ocasión de mostrar este trabajo en un evento de DAMA sobre ética el pasado mes de Junio, en la sede de Gaia-X en Talavera de la Reina.
Conseguimos con este primer entregable acaparar la atención de algunas personas, y hemos podido compartir algunas sesiones o documentación en torno a lo desarrollado tras el evento de Talavera.
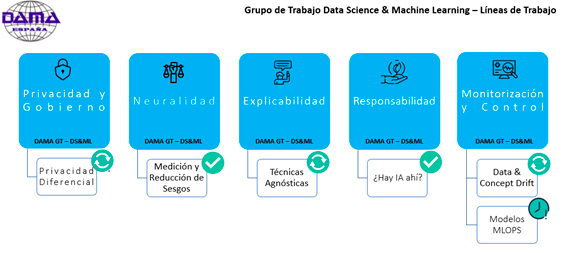
3) Explicabilidad:
En esta línea de trabajo tratamos sobre técnicas que nos permitan acompañar la salida de los algoritmos con una explicación sobre esa salida o predicción, de modo que en todo momento exista claridad indepen-dientemente del algoritmo utilizado de los motivos de cada predicción.
Esta línea está recién iniciada y está dirigida en este primer momento a la búsqueda de técnicas agnósticas, es decir que podamos aplicar de forma general independientemente del algoritmo que esté realizando las predicciones.
4) Responsabilidad:
En esta línea lo primero que nos propusimos fue el encontrar una forma de poder explicar la inteligencia artificial y lo que lleva a su alrededor relativo al mundo de los datos, a persona que no tengan una relación profesional con este mundo.
En cierto modo es la línea en la que pensamos que podíamos desarrollar desde un primer momento esa aportación que podemos hacer desde una asociación como DAMA al conjunto de la sociedad; y aunque nos costó un poco encontrar una fórmula que nos permitiese llegar, pensamos que tenemos una propuesta que hemos denominado “¿Hay IA ahí?” con la que podemos conseguir este objetivo.
Estamos en este momento comenzando a organizar junto con Eventos y Marketing, la primera puesta en escena de esta propuesta, que probablemente tendrá lugar en marzo o abril de 2023, y de la que si todo va bien tendremos a través de Marketing noticias en los primeros compases de 2023.
5) Monitorización y Control:
En este eje tenemos dos líneas de trabajo, una recientemente iniciada a petición de uno de los integrantes del grupo en la que se desarrollarán distintos procesos para el reentre-namiento de modelos; y una a la que estamos dando el retoque final, y que verá la luz en unas semanas en forma de WhitePaper, en la que hemos tratado sobre técnicas que nos permiten monitorizar y hacer un control de calidad sobre los algoritmos, midiendo lo que se conoce como “deriva de datos” y “deriva de concepto”, que nos permiten establecer unos umbrales a partir de los cuales poder decidir cuando un algoritmo puede comenzar a realizar predicciones erróneas, generar sesgos, etc., y necesita por tanto un reentrenamiento dentro de su ciclo de vida.
Cierto es que todo es mejorable, pero estamos satisfechos con nuestro primer año como grupo de trabajo. Somos un grupo pequeño si consideramos los integrantes activos, por lo que aprovechamos este canal para animar a otros socios que quieran participar en el grupo de trabajo a que se pongan en contacto con nosotros y se unan.
Está claro que supone un esfuerzo, pero el retorno es gratificante.
Finalmente, queríamos aprovechar estas líneas para desear desde el grupo de trabajo, un muy buen año 2023 a todos los socios de DAMA.